by Soontaek Lim
Share
by Soontaek Lim
")
LLaMA (Large Language Model by Meta AI) is a large language model developed by Meta Platforms, Inc. (formerly Facebook, Inc.). It is designed to tackle various tasks in the field of Natural Language Processing (NLP), including text generation, understanding, summarization, translation, question answering, and other language-based tasks.
LLaMA uses a transformer-based architecture similar to other well-known language models. The transformer architecture, through its attention mechanism, better understands the relationships between words within a sentence, thereby better grasping the context to generate more natural text or provide answers to specific questions.
In 2023, Meta released the LLaMA2 model, which was trained with 40% more data than its predecessors, making it available to anyone with simple registration through the Huggingface platform.
This article will introduce a simple way to run AI chat using the LLaMA2 model through the Text Generation Web UI. This guide is based on
the Windows environment using Anaconda. Anaconda can be installed from the following link:
1. Creating a Conda Virtual Environment
After installing Anaconda, launch Anaconda Prompt from the Windows start menu. Then, use the following commands to create a new virtual environment for this exercise and activate it:
1 conda create -n textgen python=3.11
2 conda activate textgenThe Text Generation Web UI is an application that allows users to easily use text generation models through a web interface. The project aims to make advanced AI features like natural language processing easily accessible even to non-expert users. The Text Generation Web UI is available on GitHub:
2. Installing Text Generation Web UI
1 git clone <https://github.com/oobabooga/text-generation-webui>
2 cd text-generation-webui
3 pip install -r requirements.txt1 conda create -n textgen python=3.11
3. Obtaining a Token from Huggingace
If you are new to Huggingface, you first need to sign up:
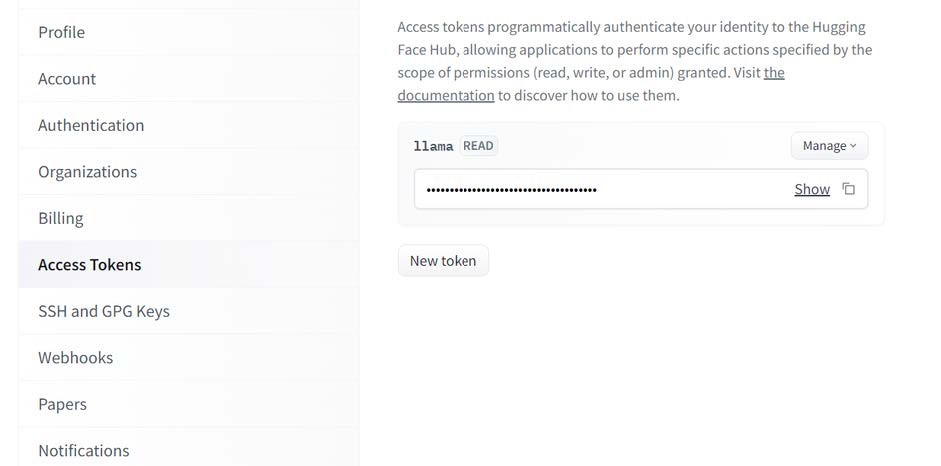
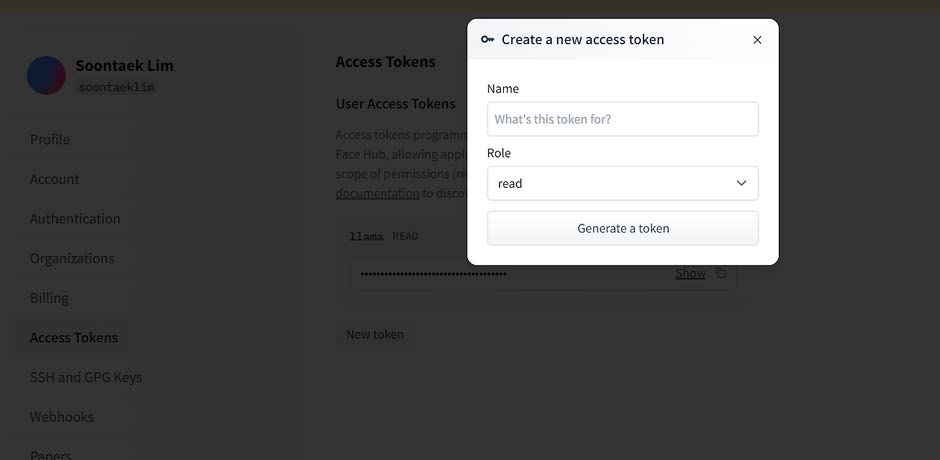
After logging in, you can find a tab to manage Access Tokens under the Settings menu in your profile. Create a token with a Read role. This token will be used to log in through the Huggingface CLI.
4. Installing Huggingface CLI
If it’s your first time using Huggingface, install the CLI in Anaconda prompt:
1 pip install -U "huggingface_hub[cli]"5. Logging in to Huggingface
Use the token generated in the previous step to log in to Huggingface:
1 huggingface-cli login
6. Downloading the LLaMA Model
LLaMA has released different models based on the size of their parameters. In this article, we will use a model with 7 billion parameters.
First, you need to apply for access to LLaMA on Huggingface, which can usually be completed within 2 hours:
Once approved, you can download the model by returning to the directory where you downloaded the Text Generation Web UI and running
the following command:
1 python download-model.py meta-llama/Llama-2-7b-chat-hf7. Running Text Generation Web UI
Execute the following command to run the Text Generation Web UI. Once the server is running, the UI will be accessible through a web browser:
1 python server.py
If everything runs without errors, the console will display URLs you can access through your web browser to see the UI.

8. Loading the Model
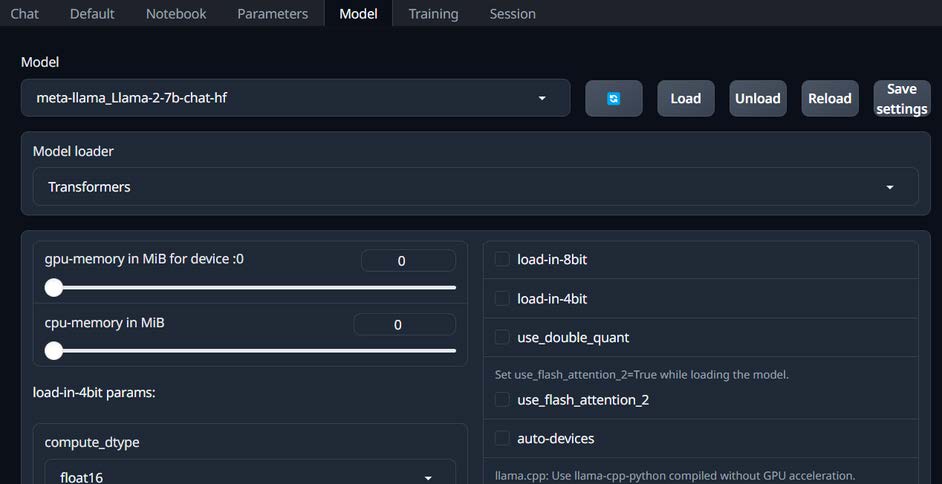
Now, you need to load the downloaded model through the UI. Go to the Model menu tab in the UI, where you can see the downloaded model and load it for use.
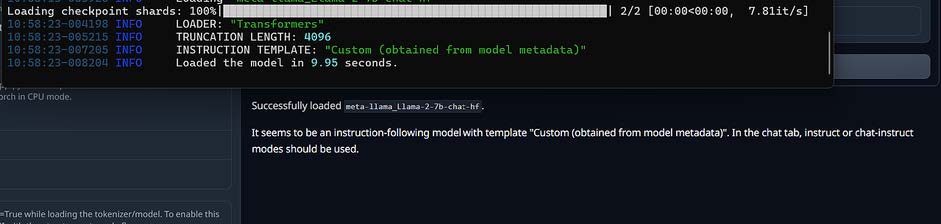
Once the model is successfully loaded, all preparations are done. Returning to the Chat menu in the UI, you can start chatting.

In conclusion, we’ve looked at how to run your own AI chat app without prior knowledge of AI. While the publicly released LLaMA still has limitations, it is open-source, and many developers are expected to quickly overcome these challenges. In fact, many fine-tuned models based on LLaMA are being developed. We can look forward to improved performance across various languages and fields in the future.



