by Fadi Wammes
Share
by Fadi Wammes
")
Introduction
In the fast-evolving world of data management, Delta Lake represents a transformative advancement, optimizing how we handle and process large-scale data with Apache Spark. As an open-source storage layer developed by the creators of Spark, Delta Lake enhances data reliability, performance, and management, making enterprise data lakes easier and more robust.
Managing complex data pipelines with traditional Spark can be challenging due to inefficient upserts, complex time travel management, and schema inconsistencies. Delta Lake addresses these issues with features that streamline operations and ensure high data quality. Its medallion architecture acts like a series of gates, ensuring only clean data progresses through its raw, curated, and serving layers. Schema enforcement prevents messy data from contaminating your pipeline while built-in versioning functions as a time machine, allowing easy auditing and rollback to previous data states.
Delta Lake also brings efficient merge operations, simplifying data integration and reducing the complexity and time needed for upserts. Performance enhancements like Z-Ordering optimize storage, speed up queries, and lower costs. Metadata management structures information effectively, and the vacuum command helps keep data organized and relevant.
By integrating Delta Lake with Apache Spark, data engineers can create scalable, reliable, and efficient data pipelines. This integration ensures higher data quality, optimized storage, reduced operational costs, and a more agile data infrastructure, making Spark a more powerful tool for modern data challenges.
Introduction to Delta Lake
Delta Lake, an open-source storage layer from Databricks, was launched in early 2019. It is designed to bring reliability and performance improvements to data lakes, seamlessly integrating with Apache Spark.
Why Use Delta Lake?
Delta Lake addresses several common issues in data management and processing:
- Open Source: Driven by community contributions and backed by Databricks with open standards and protocols.
- ACID Transactions: Ensures reliable and consistent data operations with strong isolation.
- Time Travel: Enables querying of previous data versions for audits and rollbacks.
- Schema Evolution: Supports schema changes without interrupting ongoing operations.
- Concurrent Writes: Allows simultaneous data writes, crucial for large-scale applications.
- Performance Optimization: Features like Z-Ordering and data skipping enhance query speed.
- Scalable Metadata: Manages extensive datasets with billions of partitions and files.
- Unified Batch/Streaming: Facilitates exactly-once semantics for both batch and streaming data.
- Audit History: Provides a full audit trail with detailed logs of all data changes.
- DML Operations: Offers flexible APIs (SQL, Scala/Java, Python) for data manipulation tasks.
Introduction to Apache Spark
Apache Spark is a unified analytics engine for big data processing with built-in modules for streaming, SQL, machine learning, and graph processing. Spark’s distributed computing capabilities make it a powerful tool for processing large datasets quickly and efficiently. Spark’s core features include its in-memory data processing, advanced query optimization, and support for various data sources and formats.
Spark Core: Manages task scheduling and memory management.
- Spark SQL: Provides data querying capabilities.
- Spark Streaming: Handles real-time data processing.
- MLlib: For machine learning.
- GraphX: For graph processing.

Enhancing Spark with Delta Lake
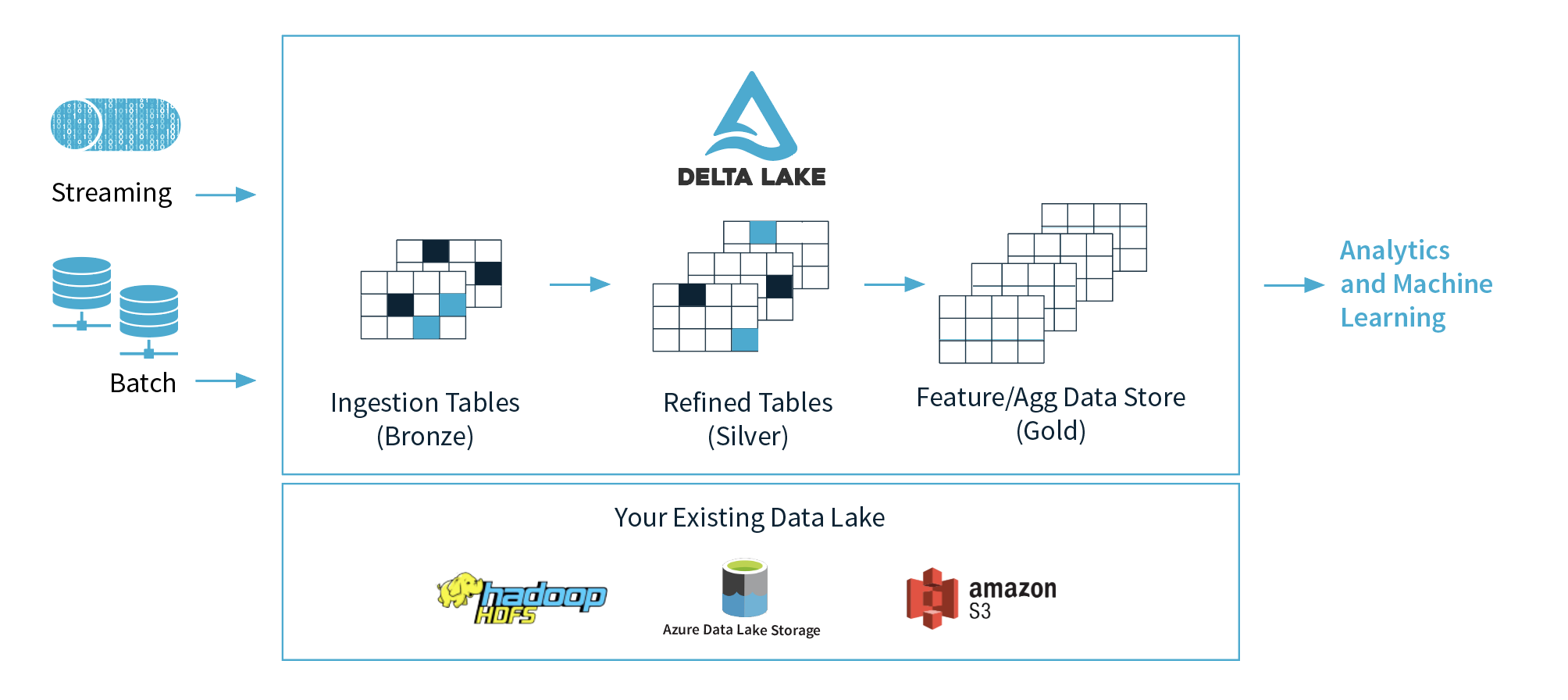
Delta Lake significantly augments Apache Spark by integrating a powerful layer that enhances data management and processing. Initially exclusive to Databricks, it’s now open source under the Apache License V2. Delta Lake integrates seamlessly with existing storage systems and provides a unified platform for batch and streaming data processing, ensuring data consistency, ease of schema management, and the ability to query historical data versions. Here’s a brief overview of how Delta Lake enhances Spark, illustrating the data flow and interaction points:
- Data Ingestion:
- Sources: Delta Lake enables seamless ingestion of data from diverse sources, including cloud object stores, databases, and streaming platforms.
- Integration: Data are ingested into Delta Lake tables, which are optimized for both batch and streaming operations. This integration supports high-throughput data ingestion with minimal latency.
- Data Processing:
- Spark Integration: Once data are in Delta Lake tables, Spark processes it efficiently using its distributed computing capabilities.
- ACID Transactions: Delta Lake provides ACID transactions to ensure data consistency during processing. This guarantees that all operations are completed correctly and rollback capabilities are available in case of failures.
- Data Management:
- Schema Evolution: Delta Lake simplifies schema management by allowing schema changes without disrupting ongoing operations. This flexibility is crucial for adapting to evolving data structures.
- Time Travel: Enables users to access and query previous versions of data, facilitating audits, rollbacks, and historical data analysis.
- Data Querying:
- Spark SQL: Users can leverage Spark SQL to execute complex queries on Delta Lake tables. Delta Lake’s optimizations, such as data skipping and Z-Ordering, enhance query performance and reduce execution times.
Delta Lake extends Apache Spark’s capabilities by offering a robust framework for data management. Its features—ACID transactions, schema evolution, and time travel—enhance Spark’s performance, data reliability, and flexibility. This integration ensures that Spark users benefit from improved data consistency, streamlined schema adjustments, and powerful querying capabilities.

Practical Example: Delta Lake with Apache Spark
This section provides a practical example of using Delta Lake with Apache Spark. For detailed setup instructions and further information, refer to the Delta Lake documentation. We’ll use Python for simplicity and demonstrate through notebook cells how to leverage Delta Lake’s features.
Setup and Initialization
To integrate Delta Lake with Apache Spark, you have several flexible options:
- Interactive Shell: Use PySpark or the Spark Scala shell for direct interaction. You can set up PySpark with Delta Lake using pip or the Scala shell using Spark’s bin/spark-shell, both with Delta Lake dependencies and configurations.
- Project Setup: Build a project with Delta Lake using Maven or SBT for Scala/Java, or configure Python projects with pip and delta-spark. This setup allows for scalable development and integration within larger applications.
Library Installation for the Demo
For the demo, we have chosen to run the code in a local Jupyter Notebook environment. Please install the necessary libraries using Python to set up the demo:
!pip install pyspark delta-spark
Make sure to have the jupyter notebook installed locally and then type on the terminal:
jupyter notebook
This command sets up PySpark and Delta Lake for interactive use and ensures you have the tools needed for data processing and management in your environment.
4.3 Setting Up Spark with Delta Lake
To start using Delta Lake with Apache Spark in your Python environment, you first need to initialize a SparkSession with the necessary Delta Lake configurations. This setup allows you to leverage Delta Lake’s features such as ACID transactions and schema evolution within your Spark applications.
Here’s how you can configure Spark with Delta Lake:
")
Loading Sample Data
This code snippet reads a CSV file into a Spark DataFrame, inferring schema and including headers. It then displays the first 5 rows of the DataFrame and provides a summary of the dataset’s statistics.
")
Writing and Reading Data with Delta Lake
This section demonstrates how to write data to a Delta Lake table and then read it back. The code saves the DataFrame to a Delta Lake table at the specified path and then reads it back into a new DataFrame, displaying the results.
")
Adding and Reading New Data with Schema Management
This section showcases how to append new data to a Delta Lake table and handle schema changes. The following code snippet demonstrates how to add new data to a Delta Lake table while managing schema evolution. It appends new records to the table and ensures consistency by showing the updated data after each transaction.
")
")
Adding New Columns and Schema Evolution
This section illustrates how to add new columns to an existing Delta Lake table and update its schema. By using the mergeSchema option, the schema evolves seamlessly, allowing for new columns to be incorporated without disrupting existing data.

Time Travel and Version Restoration
This section demonstrates Delta Lake’s time travel functionality. By specifying versionAsOf or timestampAsOf, you can query and restore earlier versions of the table, ensuring data can be recovered or audited from previous states.
")

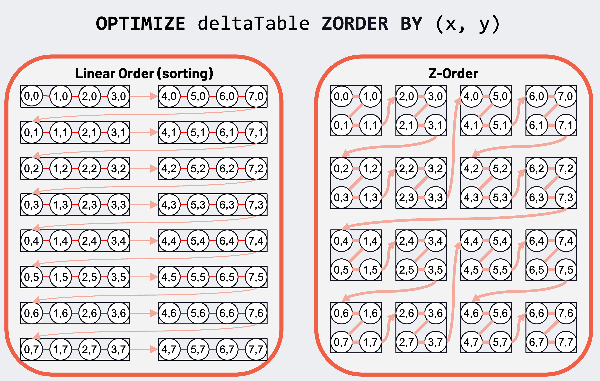
Optimizing with Z-Ordering
In this section, we use Z-Ordering to optimize the Delta table. Z-Ordering is a technique in Delta Lake that improves query performance by co-locating related data in storage. The optimize().executeZOrderBy(“PickupZip”) command reorganizes the data files to optimize access patterns for queries that filter by PickupZip. For a visual explanation of Z-Ordering and its impact on query efficiency, refer to the accompanying diagram.
Following we have this code snippet:

Streaming Data and Upsert Operations
In this section, we demonstrate how to handle streaming data and perform upsert operations with Delta Lake.
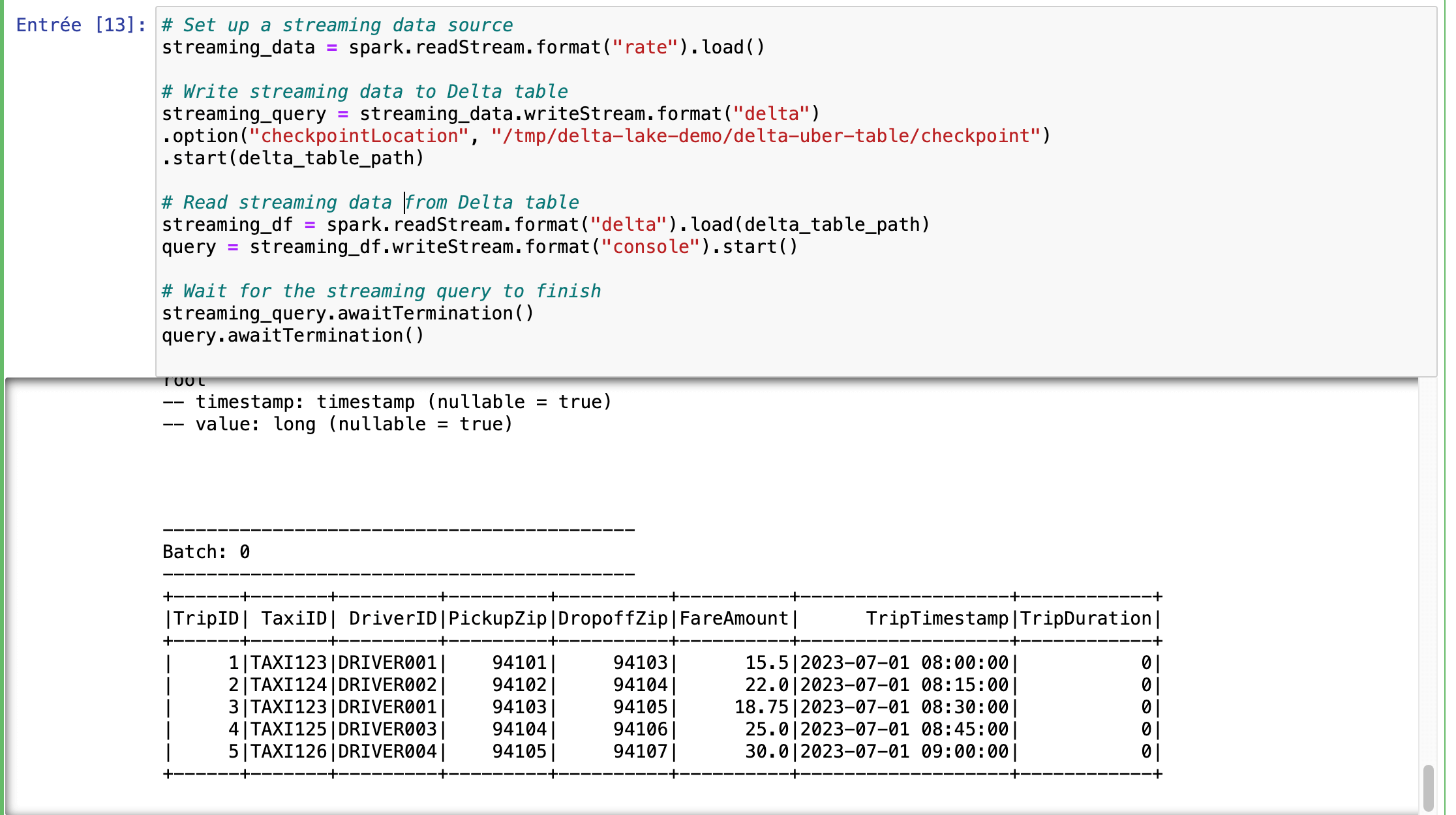
- Streaming Data Source: We set up a streaming source using spark.readStream.format(“rate”).load(), which simulates a stream of data. This data are then written to the Delta table with a checkpoint directory to ensure fault tolerance and consistency.
- Read Streaming Data: The streaming data are read from the Delta table and displayed in the console. This setup allows for real-time updates and monitoring.
- Upsert Operation: We use Delta Lake’s merge functionality to perform an upsert, which updates existing records or inserts new ones based on a matching condition. This operation is crucial for maintaining up-to-date and accurate data in real-time scenarios.
- Data Deletion and Compaction: We demonstrate data deletion and file compaction using deltaTable.delete() and deltaTable.vacuum(), which help manage data size and performance.

For a complete understanding, refer to the provided diagram illustrating the data flow and interaction between streaming data sources and Delta Lake.
spark_delta_1
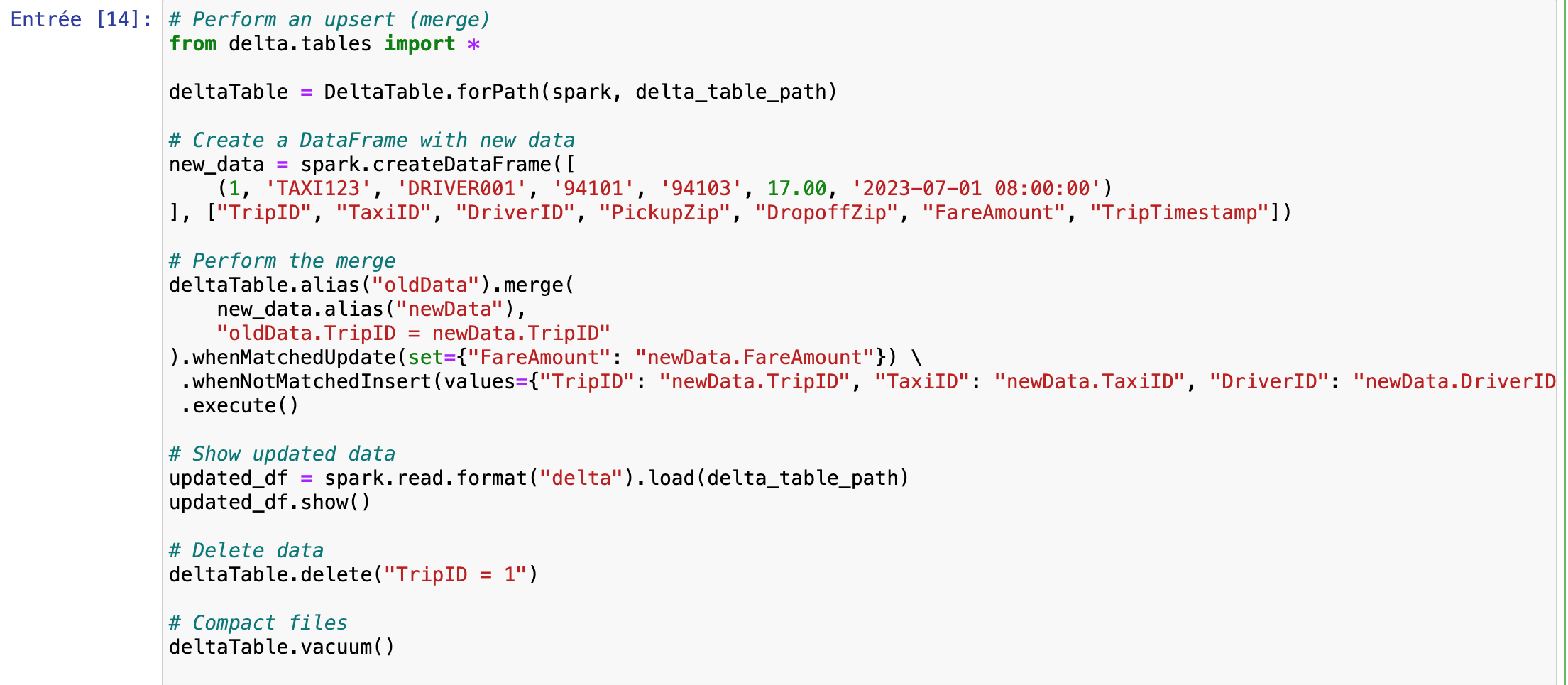
The upsert operation was successful, as evidenced by the updated first line of data. Additionally, the vacuum operation effectively cleaned up the obsolete files.

We can now verify the deletion operation by fetching the data from the stream, ensuring that the previously deleted first line no longer appears.

View Delta Table History and Clean Up
This section demonstrates how to view the historical changes in a Delta table and perform data cleanup.

This code allows you to inspect the change history of the Delta table, which helps in tracking modifications and understanding the evolution of your data. The vacuum operation is used to clean up old data files that are no longer needed, retaining only those from the last specified number of hours (168 hours = 7 days).
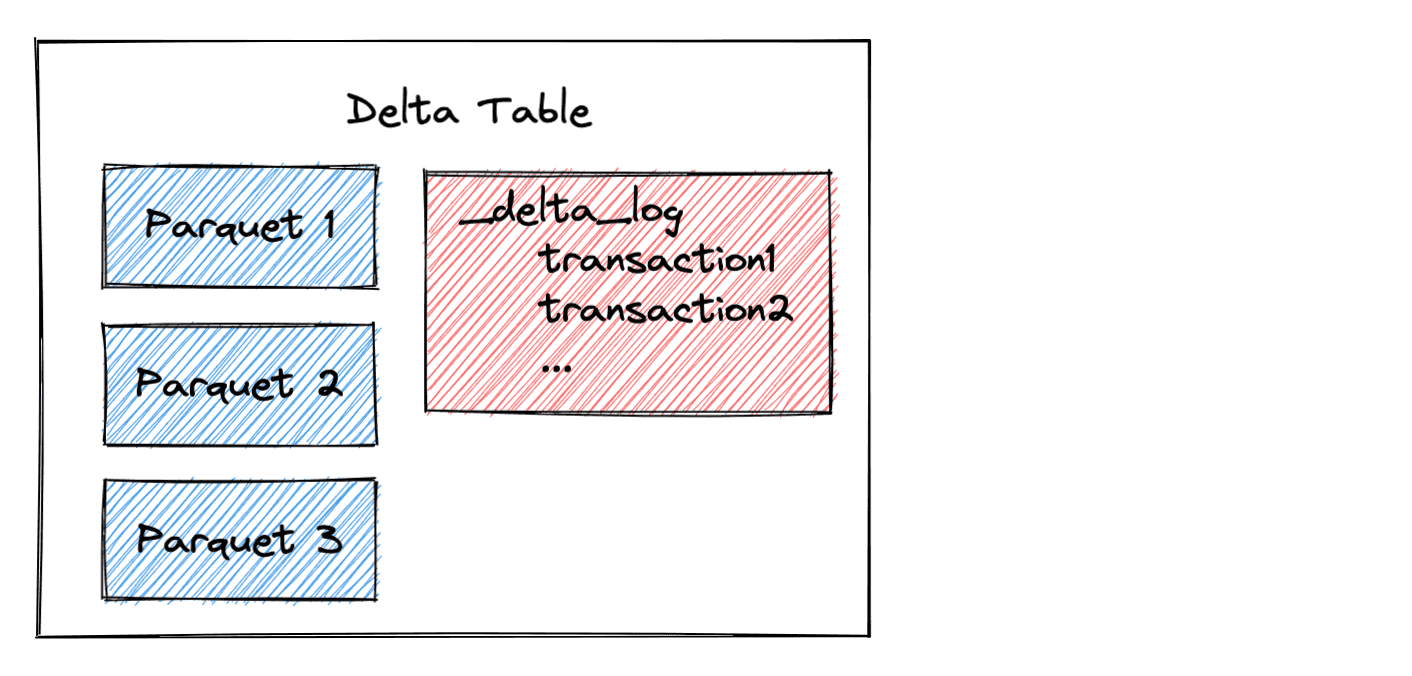
We’ll examine how Delta Lake handles metadata for scalability and auditing. Delta Lake maintains a detailed log of all changes to your data, stored as JSON files in a directory called _delta_log. These logs track every modification, addition, or deletion, providing a comprehensive history of all transactions. By viewing these logs, you can verify how Delta Lake efficiently manages metadata at scale, ensuring both scalability and auditability. I’ll make a screenshot showing the directory and these log files to illustrate how Delta Lake captures and organizes change details for robust data management.
The Core Unit of Storage
In Delta Lake, a Table is a collection of data organized into a schema and directory structure. It represents the fundamental unit of storage. Here it is the local representation of the delta table:

Closing Summary
Delta Lake’s transition to open source marks a significant milestone, unlocking its potential for broader integration and innovation. By supporting various storage systems like S3 and ADLS and multiple programming languages including Java, Python, Scala, and SQL, Delta Lake enhances its versatility. Its compatibility with Hive Metastore and the ability to manage both batch and streaming data further solidify its role in modern data architectures. The open-source nature of Delta Lake paves the way for new connectors, such as those with Presto, fostering deeper integration with diverse technologies. This move not only amplifies community engagement but also accelerates the development of new features and improvements. Despite not being designed for OLTP and having some constraints with older Spark versions and specific file formats, Delta Lake’s advancements in schema enforcement, consistency, and isolation offer a robust solution for data quality and management. Its growing ecosystem and expanding community ensure that Delta Lake will continue to evolve and deliver enhanced capabilities, making it an invaluable asset for future data engineering challenges.