by Sally Bo Hatter
Share
by Sally Bo Hatter

Die Suche ist eine wichtige Fähigkeit in der Computerwissenschaft mit zahlreichen praktischen Anwendungen. Menschen nutzen Suchtechnologien jeden Tag, wenn sie beliebte Websites und Suchmaschinen verwenden. Die Volltextsuche gibt es schon seit langem, und mit der zunehmenden Bedeutung der KI-Vektorsuche gewinnt die Volltextsuche nun an Bedeutung. In diesem Artikel vergleichen wir eine traditionelle Volltextsuche mit einer Vektorsuche unter Verwendung einer PostgreSQL-Instanz in einer Cloud-Umgebung.
Einführung
Die Vektorsuche ist eine Methode zur Suche und Einstufung von Ergebnissen, die auf der Umwandlung einer Suchanfrage in eine Vektordarstellung und dem Vergleich mit Vektordarstellungen von gesuchten Dokumenten basiert. Je näher der Vektor eines Dokuments am Vektor der Suchanfrage liegt, desto relevanter ist es. Es gibt mehrere Maßstäbe für die Nähe, darunter der euklidische Abstand, das innere Produkt oder der Kosinusabstand. Zur Erzeugung von Vektoren (auch Einbettungen genannt) wird ein neuronales Netzwerkmodell verwendet.
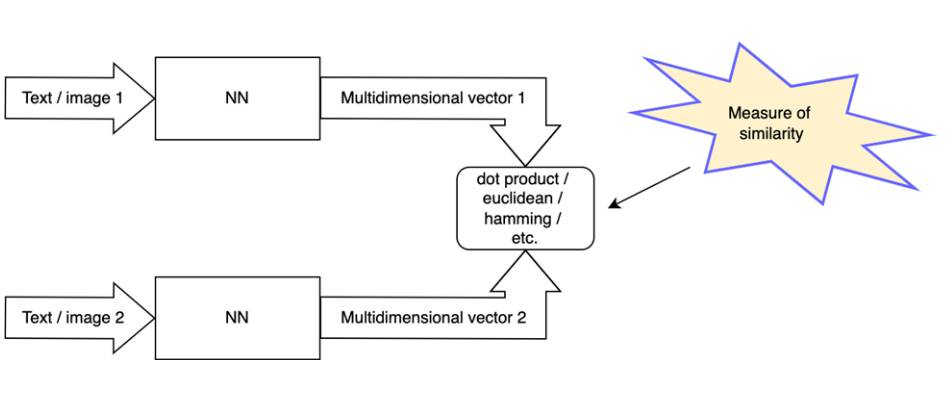
Vektoren und entsprechende Dokumente werden in einem Vektorspeicher gespeichert. Da die Anzahl der Dokumente in Vektorspeichern sehr groß sein kann, sollten Sie Indexierungstechniken einsetzen, um die Suche nach relevanten Ergebnissen zu beschleunigen. Um nur einige zu nennen:
- Lokalitätsabhängiges Hashing (LSH)
- Invertierter Datei-Index (IVF)
- Hierarchical Navigable Small World (HNSW)
- Produkt-Quantisierung (PQ), Skalar-Quantisierung (SQ)
- Zusammengesetzte Methoden, z.B. HNSW_SQ, IVF_PQ
Pgvector ist eine Erweiterung, die Vektorspeicherfunktionen in PostgreSQL bietet. Pgvector verwendet den HNSW (Hierarchical Navigable Small World) Graph für die Indizierung. HNSW ist ein mehrschichtiger Graph, der wie eine probabilistische Datenstruktur Skip-List funktioniert. Jeder Knoten im Graphen ist ein Vektor, während Kanten die nahe beieinander liegenden Knoten miteinander verbinden. Die Suche wird durchgeführt, indem von der höheren Schicht bis zur Schicht 0 hinabgestiegen wird und in jeder Schicht eine Breadth-First-Suche durchgeführt wird, um die am besten übereinstimmenden Vektoren zu finden. Bei der Volltextsuche werden Variationen von TF-IDF (Term Frequency-Inverse Document Frequency), Wortstämme, Listen von Stoppwörtern, Synonymwörterbücher und eventuell weitere regelbasierte Algorithmen verwendet. Zur Verbesserung der Suchleistung wird der invertierte Index verwendet, d.h. eine Zuordnung vom Wort zur Liste der Dokumente, in denen das Wort vorkommt, zusammen mit einigen zusätzlichen Informationen. PostgreSQL bietet die Indextypen GIN (Generalized Inverted Index) und GiST (Generalized Search Tree) sowie verschiedene Operationen für die Volltextsuche. Eingebaute Ranking-Funktionen berücksichtigen, wie oft die abgefragten Begriffe im Dokument vorkommen, wie nah die Begriffe im Dokument beieinander liegen und wie wichtig der Teil des Dokuments ist, in dem sie vorkommen.
Playground Einrichtung
In diesem Abschnitt wird kurz eine Einrichtung des PostgreSQL-Playgrounds in der Google Cloud beschrieben, um die Leistung der Indizes zu messen. Der nächste Abschnitt liefert die Ergebnisse des Vergleichs. Wir richten die PostgreSQL-Instanz mit Cloud SQL ein. Die PostgreSQL Cloud SQL-Instanz enthält standardmäßig die pgvector-Erweiterung. Wir müssen sie nur mit einer einfachen SQL-Anweisung aktivieren. Für die Erzeugung von Einbettungen sowohl für indizierte Dokumente als auch für Suchanfragen wurde das Modell textembedding-gecko@001 gemäß dem Beispiel verwendet. Mit diesem Notebook und einer kleinen Änderung im Schritt „Speichern der Einbettungen im JSON-Format“, die den Fragentitel und den Fragenteil in die JSON-Ausgabe einbezieht, können wir JSON-Dateien mit der folgenden Struktur erzeugen:
„`json [ { { “id“: 1, „embedding“: [ 0.123456789, 0.123456789, …, 0.123456789], „text“: “ Frage 1 header\nFrage 1 Inhalt“ }, { „id“: 2, „embedding“: [ 0.234567891, 0.234567891, …, 0.234567891], „text“: “ Frage 2 Kopfzeile\nFrage 2 Inhalt“ }, … ] „`
Erstellen Sie eine Cloud SQL-Instanz (ersetzen Sie den Wert von DB_PASS durch ein beliebiges Passwort, wenn Sie es ausführen):
„`shell DB_USER= postgres DB_PASS=[ password] MY_PUBLIC_IP= $(curl ipinfo.io/ip ) gcloud auth login gcloud sql instances create search-test\ –authorized-networks=${MY_PUBLIC_IP} \
–availability-type=ZONAL \ –root-password=“${DB_PASS}“ \
–storage-auto-increase \
–storage-size=10G \ –region=“us-central1″ \ –tier=“db-custom-2-8192″ \ –database-version=POSTGRES_15 „`
Beachten Sie, dass die Verbindung zur Instanz nur von der öffentlichen IP erlaubt ist, die durch die Variable MY_PUBLIC_IP definiert ist. Nachdem die Instanz verfügbar ist, stellen wir mit einem PostgreSQL-Client und der öffentlichen IP oder dem Cloud SQL Studio in der Google Cloud-Konsole eine Verbindung zu ihr her. Dort aktivieren wir die Vektorerweiterung und erstellen eine Tabelle und Indizes für den Vektor und für die Volltextsuche: Nachdem die Instanz verfügbar ist, verbinden wir uns mit ihr über einen PostgreSQL-Client und eine öffentliche IP oder Cloud SQL Studio in der Google Cloud-Konsole. Dort aktivieren wir die Vektorerweiterung und erstellen eine Tabelle und Indizes für den Vektor und für die Volltextsuche:
„`SQL CREATE IF NOT EXISTS vector; ERZEUGE TABLE IF NOT EXISTS question_store ( id interger primary key, embedding vector( 768), Inhalt text ); CREATE INDEX IF NOT EXISTS hnsw_l2 ON question_store USING HNSW (embedding_vector_l2_ops); CREATE INDEX IF NOT EXISTS search_idx ON question_store USING GIN (to_tsvector(‚english‚, content)); „`
Als nächstes laden Sie Daten in PostgreSQL. Installieren Sie gegebenenfalls das Paket psycopg2 und aktualisieren Sie die Variablen am Anfang des Skripts: Geben Sie die öffentliche IP-Adresse der Cloud SQL-Instanz als Wert für die HOST-Variable an (die IP-Adresse finden Sie in den Details der Instanz in der Google Cloud-Konsole), geben Sie das Passwort als Wert für die PASS-Variable an und aktualisieren Sie den Wert für FILE_NAME_PREFIX entsprechend. Um Verbindungsprobleme zu vermeiden, stellen Sie außerdem sicher, dass Sie das Skript von dem Rechner aus ausführen, dessen öffentliche IP bei der Erstellung der SQL-Instanz angegeben wurde. Sie können in den Einstellungen der Cloud SQL-Instanz in der Google Cloud-Konsole weitere zulässige öffentliche IPs hinzufügen:
„`python import psycopg2 import json HOST= “ 34.67.204.142″ DB= „postgres“ USER= „postgres“ PASS= „“ FILE_NAME_PREFIX= „/tmp/tmp5o9ucvho/tmp5o9ucvho_“ connection = psycopg2.connect(database=DB, user=USER, password=PASS, host=HOST, port=5432) cursor = connection.cursor() def load_vectors(i: int): result = [] with open(FILE_NAME_PREFIX + str(i) + „.json“, „r“) as vectors: line = vectors.readline() while len(line) > 0: result.append(json.loads(line)) line = vectors.readline() return ergebnis def do_upload(i: int): entries = load_vectors(i) print ( „loading „ + str(len(entries)) + “ entries“) args_str = „“ for entry in entries: id = int(entry[ „id“]) content = Eintrag[ „text“] embedding = str(entry[ „embedding“]).replace( „‚“, „“) args_str += cursor.mogrify( „(%s,%s,%s)“, (str(id), einbettung, inhalt)).decode( „utf-8“) args_str += „,“ cursor.execute( „insert into question_store(id, embedding, content) values“ + args_str.rstrip( ‚,‘)) connection.commit() print( „done „ + str(i)) for i in range(0, 10): do_upload(i) print(„finished“) connection.close() „`
Das Skript wird die Daten in mehreren Batches hochladen. Zu Beginn importiert es die erforderlichen Pakete, definiert Variablen, öffnet dann eine Verbindung zu PostgreSQL und startet eine Transaktion. Die Funktion load_vectors() liest die zuvor generierten Daten im JSON-Format aus Dateien, deren Speicherort durch die globale Variable FILE_NAME_PREFIX definiert ist, z.B. /tmp/tmp5o9ucvho/tmp5o9ucvho_0.json, /tmp/tmp5o9ucvho/tmp5o9ucvho_1.json, usw. Die Funktion do_upload() liest die JSON-Datei und bereitet eine Insert-SQL-Anweisung mit den Einbettungen vor, führt sie aus und überträgt die Transaktion. Schließlich durchläuft das Skript 10 Iterationen (eine Iteration pro Datei), wobei jedes Mal do_upload() aufgerufen wird. Um die 5 wichtigsten Stack Overflow-Fragen auszuwählen, die für Ihre Anfrage am relevantesten sind, können Sie die SQL-Anweisungen verwenden: „`SQL SELECT Inhalt, Einbettung <-> ‚[1,2,3]‘ AS disctance FROM question store WHERE embedding <-> ‚[1,2,3]‘ < 1 ORDER BY Abstand LIMIT 5; SELECT id, Inhalt FROM ( SELECT id, inhalt, ts_rank_cd(to_tsvector(‚ english‚, inhalt), query) AS rang FROM question_store, to_tsquery(“) query WHERE query @@ to_tsvector(‚ englisch‚, inhalt) ORDER BY rank DESC LIMIT 5) as t „`
Die erste Anweisung verwendet die Vektorsuche und den HNSW-Index. Relevante Vektoren können aus dem Text der Suchanfrage mit Hilfe des zuvor erwähnten Modells textembedding-gecko@001 generiert werden, indem Sie die im Notebook definierte Funktion encode_texts_to_embeddings() aufrufen (was kein Problem sein sollte, wenn Sie es bis hierher geschafft haben). Die zweite Anweisung verwendet die Volltextsuche, wobei der Text der Suchanfrage direkt in der Anweisung als „“ angegeben wird.
Ergebnisse und Schlussfolgerung
Verwendung der Systemansicht pg_stat_statements und Funktionen pg_relation_size, pg_total_relation_size können wir Informationen über die Ausführungsgeschwindigkeit und den Umfang der Volltextsuche und der Vektorsuche gewinnen:
| Name | Werte |
|---|---|
| Anzahl der Zeilen | 50000 |
| Tabellengröße mit Indizes | 489 MB |
| Größe des HNSW-Index | 195 MB |
| Größe des GIN-Index | 40 MB |
| Typ | min_exec_time (ms) | max_exec_time (ms) | mean_exec_time (ms) |
|---|---|---|---|
| Vektor (HNSW) | 2.4 | 5.0 | 3.4 |
| Volltext (GIN) | 1.4 | 871.9 | 101.2 |
Wie wir sehen können, ist der HNSW-Index 2,5 Mal größer als der GIN-Index für dieselben Daten. Die Volltextsuche hat eine höhere Varianz in der Abfragezeit. Sie ist im Durchschnitt langsamer, aber wir müssen bedenken, dass wir zur Durchführung von Vektorsuchen auch Einbettungen aus der Textabfrage generieren müssen. Es dauert etwa 100 ms, um einen Vektor mit Hilfe eines API-Aufrufs an textembedding-gecko@001 in derselben Region zu erzeugen, in der das Modell gehostet wird. Aus qualitativer Sicht ist die Volltextsuche starrer und vorteilhafter für die Suche nach exakten Übereinstimmungen und Begriffen, während die Vektorsuche besser für die Suche nach der Bedeutung geeignet ist. Außerdem kommt die Vektorsuche besser mit grammatikalischen Fehlern in der Suchanfrage zurecht. Wenn man den Ressourcenverbrauch im Verhältnis zur vollen CPU- und Festplattenkapazität betrachtet, belaufen sich die geschätzten Kosten für 10.000 Vektorsuchanfragen pro Tag mit einer durchschnittlichen Länge von 100 Zeichen pro Anfrage auf etwa $2,00, einschließlich der Kosten für die API-Aufrufe zur Erzeugung der Einbettungen. Bei einer Volltextsuche mit ähnlichen Merkmalen liegt der Preis bei weniger als $1. Sie können den Preisrechner von Google Cloud verwenden, um die Kosten zu schätzen. Wenn Sie die Schritte zur Erstellung des Spielplatzes befolgt haben, vergessen Sie nicht, die Cloud SQL-Instanz abzubauen und andere Ressourcen zu bereinigen, die Sie möglicherweise in GCP zugewiesen haben.



